Abstract 정리
Offline RL 특징
- have potent in many safe-critical tasks in robotics where exploration is risky and expensive. (로봇 같은 경우 exploration을 잘못하다가 하드웨어 등이 손상이 갈 수 있기 때문)
- still struggles to acquire skills in temporally extened tasks. (temporally exteded task가 뭐지??)
이 논문 특징
- temporally extended tasks를 위해 사용.
- hierarchical planning framework 사용 (low-level goal-conditioned RL policy와 high-level goal planner).
- low-level policy는 offline RL로 training 하여 out-of-distribution (OOD) goal을 다룸.
- high-level planner는 model-based planning 방법 사용하여 intermediate sub-goals 선택.
- future sub-goals은 learned value function of the low-level policy를 base로 하여 plan.
- Conditional Variational Autoencoder (CVAE) 사용하여 meaningful high-dimensional sub-goal candidates를 sampling 함.
- high-level long-term strategy optimization problem을 푸는 방법 사용.
Introduction 정리
RL 특징
- complex tasks with extened temporal duration를 풀기에는 쉽지 않다. 특히 exploration이 risky 하고 expensive 한 safety-critical applications (e.g., autonomous driving)에서는 적용하기 어렵다.
Offline RL 특징
- RL의 단점을 보안하기 위해 offline RL을 사용하여 static offline datasets을 이용해서 RL policy들을 train.
- 하지만 지금까지 temporally extended task들을 위해 의도적으로 조사한 연구는 없음.
이 논문 특징
- 따라서 이 논문에서는 temporally extended task들을 RL을 이용한 연구하기 위한 목적으로 쓰임. (이 논문의 목적) 이를 통하여 RL을 이용하여 intelligent agent들을 complex and safety-critical environment에서 navigate 할 수 있다.
- extended temporal duration을 다루기 위한 방법으로 hierarchical framework를 사용.
- low-level policy controlling the agent를 사용해서 short-term tasks를 수행하며 high-level module로부터 supervision을 받는다. high-level module은 long-term stategy에 대해 reasoning을 함.
- high-level module로는 model-free RL과 planning module이 사용될 수 있는데 이 논문에서는 low-level goal-conditioned RL policy와 high-level model-based planning module을 combine 하여 사용. High-level module은 sub-goal sequence와 함께 goal-reaching policy를 guiding 한다.
- High-level module은 long-horizon tasks을 다루는데 이건 특히 offline setting에 적합하다. 그 이유는 이것은 offline dataset으로부터 short-horizon goal-reaching policy learning만 필요로 하기 때문이다 (이 말이 이해 안 됨). 이건 entire task를 푸는 end-to-end policy를 직접 learning 하는 것보다 훨씬 쉽고 data-efficient 하다.
방법론 설명
- Hindsight Experience Replay (HER)를 leverage 하여 static datasets으로부터 goal-conditioned episodes을 synthesize 한다.
- 그러고 나서, SOTA model-free offline RL을 이용하여 policy를 training 한다.
- OOD goals로부터 발생하는 distributional shift를 해결하기 위해 noisy unreachable goals을 perturbed goal sampling process를 통하여 생성하는 방법을 propose 한다. 이 noisy goals은 high-level planner에 OOD goals을 online execution동안 피할 수 있게 한다.
- high-level sub-goal planner는 low-level policy를 위해 intermediate sub-goals에 대해 plan 한다. 특히, low-level policy의 goal-conditioned value function을 기반으로 하여 optimization 문제를 푼다.
- efficient online computation을 보장하기 위하여, CVAE를 train 하여 feasible 하고 reasonable 한 goal sequence를 제안한다. (CVAE를 사용하는 게 왜 efficient online computation을 보장? 그리고 왜 feasible 하고 reasonable?)
Related Works 정리
Hierarchical framework
- long-horizon tasks를 다루는데 장점이 있음.
- Conventional hierarchical RL은 action space를 직접적으로 decompose 함.
- 최근 연구에서는 high-level과 low-level components로 나눈 architecture designs이 많이 사용됨. (e.g., high-level graph search-bese planner, two-phase training, mixed imitation learning and reinforcement learning policies, and high-level latent primitive extraction.) 이러한 연구들은 multiple policy들을 online에서 training 함.
- 해당 논문에서는 static offline data로부터 only one RL low-level policy training만 필요함.
- 또한, value function은 whole MDP를 사용하는 대신, 연속된 sub-goals사이의 short MDP에 대해서만 high-level planner에 의해 사용됨. 그 결과로, entire episode 대신에 sub-goals 사이의 short horizon에 대한 expected future return의 추정치만 요구된다. 추가로, long-term strategies에 대한 reasoning ability를 향상해 주는 multiple look-ahead timesteps을 고려할 수 있다.
Planning with goal-conditioned Policies [11]
- base로 한 [11] 논문은 goal reaching의 single objective와 함께 finite-horizon goal-conditioned MDP를 위하여 개발되었다.
- 이와 대조적으로, 이 논문은 reachability 이외의 criteria (e.g., comfort, safety)를 고려할 수 있기 위해서 goal-conditioned가 아닌 MDPs로 문제를 일반화하였다. (정확히 이해 안 감)
- [11]에서는 online optimization을 하는 동안 efficient sub-goal sampling를 하기 위해 high-dimensional image observation을 모델링하는 VAE를 채택하였다.
- 이 논문은 VAE대신 CVAE를 사용하여 optimization performance를 향상하는 sub-goal sequences를 sequentially 샘플링하였다. (CVAE를 사용하면 sequentially sampling 하는 건가? sub-goal sequences를 sequentially sampling 하면 optimization performance가 향상되는 건가? 왜?) - CVAE가 current state를 조건으로하여 variance를 VAE에 비해 줄이고 그에 따라서 sampling efficiecy가 향상되고 optimization performance가 향상됨.
- online exploration과 함께 low-level policy와 value function을 learning 하는 [11]과 다르게 이 논문의 framework는 offline setting으로 개발되었다.
Methodology 정리
Problem Formulation
- RL을 이용하여 MDP를 풀 때 중요한 요소는 value fucntion under a policy이다.
- Value function estimation은 present observation의 neighborhood에 points을 predicting 하는데 정확한 경향이 있다.([25] When to trust your model: Model-based policy optimization)
- big task를 small pieces로 break 하는 건 reasonable 한데, 이 policy는 가깝고 정확한 goal points에서 values을 predict 하는 value function이 only 필요하다. 이러한 insight를 기반으로, high-level planner는 sub-goal selection에 responsible 하고 low-level goal-conditioned policy는 executable actions 생성에 responsible 한 hierarchical policy를 가진 MDP를 푼다.
- a planned sub-goal at $t_i$ 가 주어진 상태에서, low-level policy가 $t_i$와 $t_{i+1}$사이의 각 time step에서 agent를 desired sub-goal at $t_{i+1}$로 controlling 하는 actions을 생성한다.
- low-level goal-conditioned policy is denoted by $\pi(\textbf{a}_{t_{i,j}} | \textbf{s}_{t_{i,j}}, \textbf{g}_{t_{i+1}})$. $ \textbf{g}_{t_{i+1}} $is the sub-goal for $t_{i+1}$.
Hierarchical Goal-Conditioned Offline Reinforcement Learning

A. Generating High-level sub-goals (어떻게 sub-goals을 생성하는지)
- low-level policy는 a single sub-goal만 필요하지만, 이 planner는 optimal long-term strategy를 보장하기 위하여 multiple sub-goals을 future로 optimize한다.
- 이 문제는 constrained optimization problem으로 formulation 될 수 있다: multiple future steps을 위해 cumulative reward를 sub-goals에 대해 low-level policy의 reachable한 sub-goals의 constraint와 함께 maximizing을 한다.
- sequence of $H$ sub-goals이 solution이다.


- $r_{env}$ 는 original MDP env로 정의된 reward function.
- $r_{TDM}$ 은 주로 prior goal-conditioned policy learning works에서 사용된 temporal difference model (TDM)으로 정의된 auxiliary goal-conditioned reward function.

- $d$ 는 tasks에서 특정된 distance function.
- 정의에 의해서 TDM reward는 항상 non-positive인데 (1)의 constraint에 의해서 expected cumulative reward $r_{TDM}$은 non-negative이다. 그 결과로, feasible $\textbf{g}$는 all time steps에서 $r_{TDM} = 0$이다. 이는 $\textbf{g}$가 항상 reachable하다는걸 guarantee한다는 의미이다.
- Problem (1)의 optimal solution은 lagrangian function인 max-min optimization problem이다.

- augmented value function인 $V^{\pi}$는 augmented reward function $r_g$와 관련된 low-level policy $\pi$의 value function이다.

- dual gradient descent를 이용하여 $g$와 $\beta$를 iteratively update할 수 있지만, online running을 위하여 Lagrangian relaxation of Problem (2)를 이용한다. 이는 $\beta$를 unconstrained maximization problem으로 relax하기 위해 prefixed value로 지정하는 방법으로 multiplier $\beta$는 objective와 regularization term 사이의 trade-off factor이다.
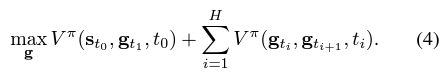
- Problem (4)를 풀기위해 cross-entropy method(CEM)을 optimizer로 사용함.
- high-dimensional images을 observation으로 사용함.
- meaningful images을 sampling하기 위하여 CVAE를 사용.
CVAE에 대한 설명
- inference mapping, i.e., encoder $E_{\mu}(\textbf{z}|\textbf{g}_{t_i}, \textbf{g}_{t_{i+1}})$, and generative mapping, i.e., decoder $D_{v}(\textbf{g}_{t_{i+1}} | \textbf{g}_{t_i}, \textbf{z})$.
- Inference network는 prensent goal state $\textbf{g}_{t_i}$를 latent state $ \textbf{z}$에 next goal $ \textbf{g}_{t_{i+1}}$를 조건으로 하여 mapping한다.
- Generative mapping은 opriginal input $ \textbf{g}_{t_i}$를 조건으로 하여 next goal $ \textbf{g}_{t_{i+1}}$에 latent state $ \textbf{z}$를 mapping한다.
- latent state $ \textbf{z}$는 low-dimensional하고 specified prior distribution $p( \textbf{z})$를 따른다.
- 이 distribution approximating goal distribution으로부터 goal states을 sampling한 이미지들은 더 meaningful하다.
- VAE와 달리 현재 state를 조건으로하여 goal state sampling한 결과는 variance가 더 적고 sampling efficiency가 올라가기 때문에 optimization performance가 올라간다.
Objective function은 latent representation $\textbf{z}$에 대해 optimized 될 수 있다.
B. Goal-conditioned Offline Reinforcement Learning (어떻게 sub-goal planner와 goal-conditioned policies이 combine 되는지)
- static dataset으로부터 low-level policy를 train하기위해, Offline RL과 goal-conditioned training techniques을 결합하는게 목적이다.
- 특히, Eqn. (3)에서 policy $\pi$ 뿐만 아니라 value function $V^{\pi}$도 train 해야한다.
1) Relabeling the Expert
- goal-conditioned policies를 train하기 위한 pre-collected datasets은 단지 state와 action transition pairs와 corresponding rewards만 가지고 있기 때문에 goal을 가지고 있지 않다. 따라서, training동안 각 sampled state-action pair에 따른 goal을 생성해줘야한다.
- Trajectory는 그 states중에 어느 state든 goal로 유효하다.
- 그러므로 HER[16]을 따라서, whole trajectory중에 random future state인 $\textbf{s}_{\tau}^{k}가 goal로서 relabel된다.
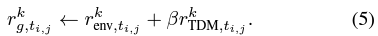
2) Robust to Distributional Shift
- OOD goals을 handling하기 위해 지금까지의 연구들은 굉장히 풀기 어려운 dynamic model to estimate state uncertainty가 필요했다.
- 대신에 이 논문에서는 새로운 noisy (probability $\eta$와 reward $r_{g,t_{i,j}}^k$로 relabeled된)로 sampled된 data point의 goal을 perturb하는 새로운 방법을 제시한다.
- 이러한 방식으로, 이 sampled data의 $\eta$-portion goals이 noisy가 되고 이 dataset에서 never achieved 하기 때문에 OOD goals을 penalize한다. 그러므로 이런 TDM rewards는 항상 negative이다.
- 그러므로, 같은 value function을 사용하는 high-level goal planner는 OOD goal의 low value areas을 피하도록 encouraged 되고 이는 test time동안 low-level policy에 implicitly하게 영향을 준다.
C. Practical Implementations (어떻게 goal-conditioned policies가 offline RL로 train 되는지)
Hierarchical Goal-Conditioned offline RL (HiGoC) framework라고 불리는 practical implementation을 formulation하기 위해 high-level goal planner와 low-level goal-conditioned policy를 integrate한다.
- dataset의 goal distribution을 modeling하기 위해 우선 CVAE가 train 되고 Conservative Q-Learning (CQL)을 이용하여 low-level goal conditioned policy와 이에 따른 value function도 train 된다. (Algorihm 1 참조)

Experiments 정리
main answer for the following questions:
- HiGoC가 다른 end-to-end RL policy 와 다른 hierarchical baselines보다 better performance 인가?
- goal-selection optimization problem에서 longer look-ahead horizon $H$가 better performance를 lead 하는가?
- value function이 효율적으로 different goal points의 optimality를 encode 하는가?
- perturbed goal sampling process와 CVAE가 hierarchical planner의 performance를 향상 시키는가?
A. Experiment Settings
1) Carla simlurator
- reward는 safety와 efficiency of driving을 평가하여 주어진다.
- 30개의 obstacle vehicles를 이용하여 interactions with surrounding vehicles를 simulate한다.
- 우선 roundabout이 포함된 제한된 구역안에서 evaluation한 뒤, 전체 구역에서 ability in building reliable policies을 evaluate한다. map은 "Town03" 사용.
- training을 위한 expert는 soft actor-critic (SAC)방법을 이용하여 train하였고 expert를 실행시켜 trajectories을 record하였다. 그후 HiGoC를 offline setting으로 train하였다. test time동안에는 trained policies로 agent를 drive하였다.
- "Medium"과 "expert" 총 2가지 다른 levels of quality의 dataset을 준비하였다. "Medium" dataset은 SAC를 이용하여 처음 training하고 early stopping한 half-trained expert로 collected된 data이고, "Expert" dataset은 fully trained expert dataset이다.
(작성 중)



